Mastering Effective Prompting Part 3

This is the last part in the series, you can find first two here:
Introduction
In this article, I will show you how to use your chatbot to improve your prompt, how changing your prompt structure affects the response, and how to deal with long chats.
AI-assisted Prompt engineering
Before we dive into all the "howto"s, let me remind you why how you prompt matters (I go in-depth on that subject in Part 1). In short, the more information (context) you give the model, the more helpful it is (to a certain extent). When chatting with an LLM, you are extracting information, and the goal is to extract the information you are looking for, not just random trivia. With the diagram below, I am trying to help you visualize that.
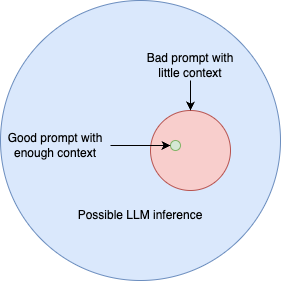
The best answer to your question is a tiny area on LLM's wide circle of possibilities. The whole thing of effective prompting, and I would argue one of the most essential skills of the foreseeable future, is to narrow the scope of LLM's creativity as close to the information you are looking for as possible. Imagine that as you provide more context, the circle of possible answers shrinks, and you come closer to the ideal answer.
In my experience, LLMs are not actually good at prompt engineering, they were not trained on that kind of data yet. However, they are good at inferring meaning. So you are not really asking ChatGPT to build you a prompt that you can use as-is, you are asking it to provide more context for the prompt you are engineering.
Now, let's look at an example of such a prompt. In this example, I am reproducing the process I have used to create the example from Part 2's "Steering AI Conversations." You already see in this prompt that the first message looks very generic. This should not be a surprise for you. It is my prompt template that I use to start a conversation about prompt engineering. Other than that, it is just a discovery process. Given that the chatbot can follow initial constraints, you can iteratively build your prompt.
The prompt in the example looks ok, but I would not use it as is. I will keep some of the structure but add more instructions independently. I am sure that in the coming versions of base models, we will see "Prompt Engineering" as part of training datasets. However, until that happens, you would likely be better at this task than the LLM.
Key Takeaways:
- Chatbot interaction will provide better results in a more narrow context.
- Use chatbot to help you with any task, including chatbot interaction.
- In my experience, for now, at least, LLMs are not good at prompt engineering itself, so tune the prompt LLM gives you.
Prompt Structure
My prompting improved significantly after taking a DeepLearning.AI course called "ChatGPT Prompt Engineering for Developers." If you are a developer, definitely take the course. If you are not, it might be a bit challenging since you would use OpenAI's API, not ChatGPT. At the time, my prompts were just short blobs of text. What "jumped" at me immediately was how structured their prompts were.
Delimiters
Very often, you would ask your friendly chatbot to summarize some text for you, or you would give it an email you want to send, and you want it to check correctness. It is crucial to clarify what you are referencing in your prompt. To make it clear for the chatbot, use delimiters like """, or ```, or maybe use tags like <email>...</email>. That will let the model know exactly what you are referencing in your prompt. So instead of:
Translate this email to Spanish
email text
Do:
Translate text surrounded by triple quotes to Spanish:
"""
email text
"""For short messages, that would not make much of a difference, but when you have multiple blocks of text you want to reference, it will yield much better results.
Formatting
My guideline for prompt structure is, "If it is hard for me to understand, it is hard for the model, too." That is why I spend time formatting my prompts. Let's take a look at one of the examples from OpenAI's GPT best practices(we have looked at it in part one):
Problem Statement: I'm building a solar power installation and I need help working out the financials.
- Land costs $100 / square foot
- I can buy solar panels for $250 / square foot
- I negotiated a contract for maintenance that will cost me a flat $100k per year, and an additional $10 / square foot
What is the total cost for the first year of operations as a function of the number of square feet.
Student's Solution: Let x be the size of the installation in square feet.
1. Land cost: 100x
2. Solar panel cost: 250x
3. Maintenance cost: 100,000 + 100x
Total cost: 100x + 250x + 100,000 + 100x = 450x + 100,000
You can see in the example above they use ordered and numbered lists. They start each section with a name, Problem Statement and Student's Solution.
Even though you can't use text editing tools to make text bold, add headers, etc., you can still express it in plain text.
You can highlight your prompt using Markdwon. Markdown is a format used mostly by software developers because it allows text formatting using simple rules in plain text. The thing is, LLMs are trained on datasets that use Markdown, and GPT models, in particular, answers using Markdown formatting by default.
The main point here is to use formatting and structure to convey meaning to the Model. In my experience, having a clear structure produces better results, but I would urge you to experiment with this for yourself
Key Takeaways:
- Use structure and formatting to convey meaning.
- Use delimiters when providing quotes or if you need to reference a part of your prompt.
The Challenge of Forgetful AI
I have spoken about the issue of the Context Window in Part 1. Just to remind you, LLM, and by extend your chatbot, has a strict limit of data it can ingest and produce (You can find token limits for OpenAI's models here). The way the chatbot works is each time you send a message, it takes all previous interactions (your messages and its messages) and processes that data, producing new text (tokens).
How (I think) ChatGPT handles large chats
"But hold on, I have chats much longer than the token limit. How does that work?" Ah, I am happy you have asked. In short, the answer is "It depends." Some chatbots just tell you that you have reached the limit and need to start a new chat. As for ChatGPT, I can speculate.
One of the common uses of LLMs is summarization. OpenAI has a few interesting papers on that subject (I recommend reading Summarizing books). To not go too deep into technicalities, what I think is happening is that when ChatGPT detects you are reaching some limit of tokens or characters, it will perform a summarization of the previous conversation. It will then substitute your previous conversation with the summary it wrote. So, the longer your conversation is, the more details your previous conversation are lost in that summarization. That is why, I think, it starts forgetting your previous instructions or any information you have given previously while having a general understanding of what was discussed. In the sequence diagram below, I tried to illustrate how this process would work:
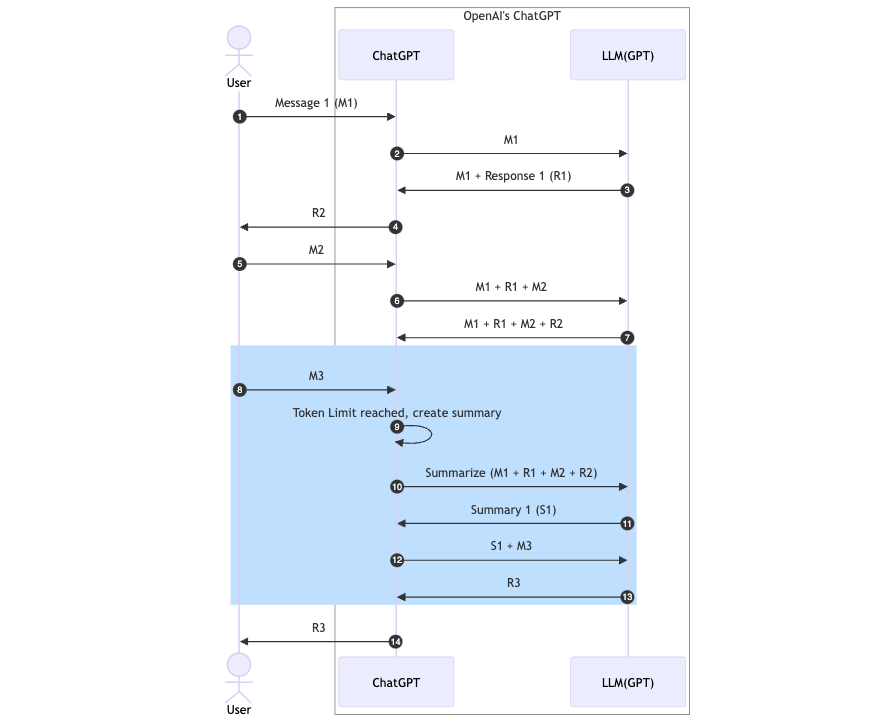
So, eventually, LLM would not be given your previous messages but the summary of your communication. And then, a summary of a summary, and so on. Again, remember that this is just my speculation on how it might work.
It matters because that is the constraint that you have to work around. Eventually, your chat history will be so condensed that the model will be given very little information about your previous communication.
How to work around that
Depending on your particular situation, you can:
- Start a new chat. In this way, all the information you provide to the model will reach the model as-is. Given that, your initial message and the AI's reply fit into the limit.
- If you notice the model forgot some information, remind it what to do. I usually do something like
Please follow these instructions: """ initial prompt""", whereinitial prompt, is the first message I have given. - Be frugal with the information you provide, and more importantly, start with clear instructions on the model's output. You can heavily reduce its output by asking to reply in a specific format and only giving specific information. For instance,
You need to return only the code no explanations or usage examples.
Conclusion
In this article, you have learned how to use a chatbot to build better prompts, how prompt structure might improve the results, and how to manage long chats.
There is so much more you can do to improve your prompts. I encourage you to explore on your own and, equally important, experiment. Try using a chatbot to solve any problem, and if it fails, try again and again until you learn how to make it solve the issue. Even if you can't, you will learn what is not possible. "Practice makes perfect" is the mantra I tell my kids when they cannot do something because it works for me.
You would need to code to harvest the true power of LLMs, and that is where I will shift the focus for now. You can turn Chain of Thought to Chain of Thought with Self Consistency, use Tree Of Thoughts for complex problem-solving, or create a whole town populated with AIs. I will transition to the subject of AI agents, but the lessons learned in this series are very much applicable there as well.



Comments ()