We need a new compiler
The reason vast majority of software is written in higher-level languages like Java, Python, C++ is that it is much, much easier, faster, and better in almost every conceivable way than Assembly. Though, when those new languages came around people working with Assembly were skeptical, because you could not control things at the level they were used to. I love how Kent Beck described it in his article More What, Less How.
I argue that we are well beyond the point where a new "programming language" could have replaced much of traditional (nowadays) programming. Just as high-level languages abstracted away the complexities of Assembly, we're now at a juncture where we can abstract away even more. This new "language" isn't about syntax or control structures, but about data itself. By shifting our focus from "how" to code to "what" we want to achieve, we can revolutionize software development in ways that parallel the shift from Assembly to high-level languages. I foresee the impact on our industry being comparable in the magnitude to the one caused by transition from Assembly and punch cards.
Data as the New Programming Language
The main point is that natural language can't be used to clearly define behaviour of a software system but data can. And by "data" I mean input/output examples, or in the otherworlds "tests". Indeed through the decades of programming, whatever the programming language we have used, or applications we developed one thing stayed constant. We always need to test software to know it does what it supposed to.
It is possible now to consistently build software based on tests alone. Besides functioning products like Svtoo's Micro, there is a paper on this subject too. Where authors proved, among other things, that using tests improves code generation accuracy (correct functionality was developed) from 19% (GPT-4) to 44%.
To simplify, I will be calling this new programming language "Software V2".
I have written an article on this subject if you are interested to learn more.
The New Compiler
Now that we have at least an abstract understanding of the new programming language (Software V2), all we need is a "compiler" to translate this language into an executable software.
Before we dive into how such a "compiler" would work, let's first define what it needs to do. We already established that simply spitting out code is not useful. So we want this compiler to:
- Produce executable software. Depending on type of software it could be:
- A native (Android, iOS, Windows, etc.) application that is ready to use.
- Web UI/API application that is deployable with no alterations.
- Alter the logic of software by changing Software V2 only, no alteration of the compiler's output.
With these two simple requirements we can not only build new software but more importantly maintain and evolve it using Software V2.
Now let's discuss how such compiler would work at a high level:
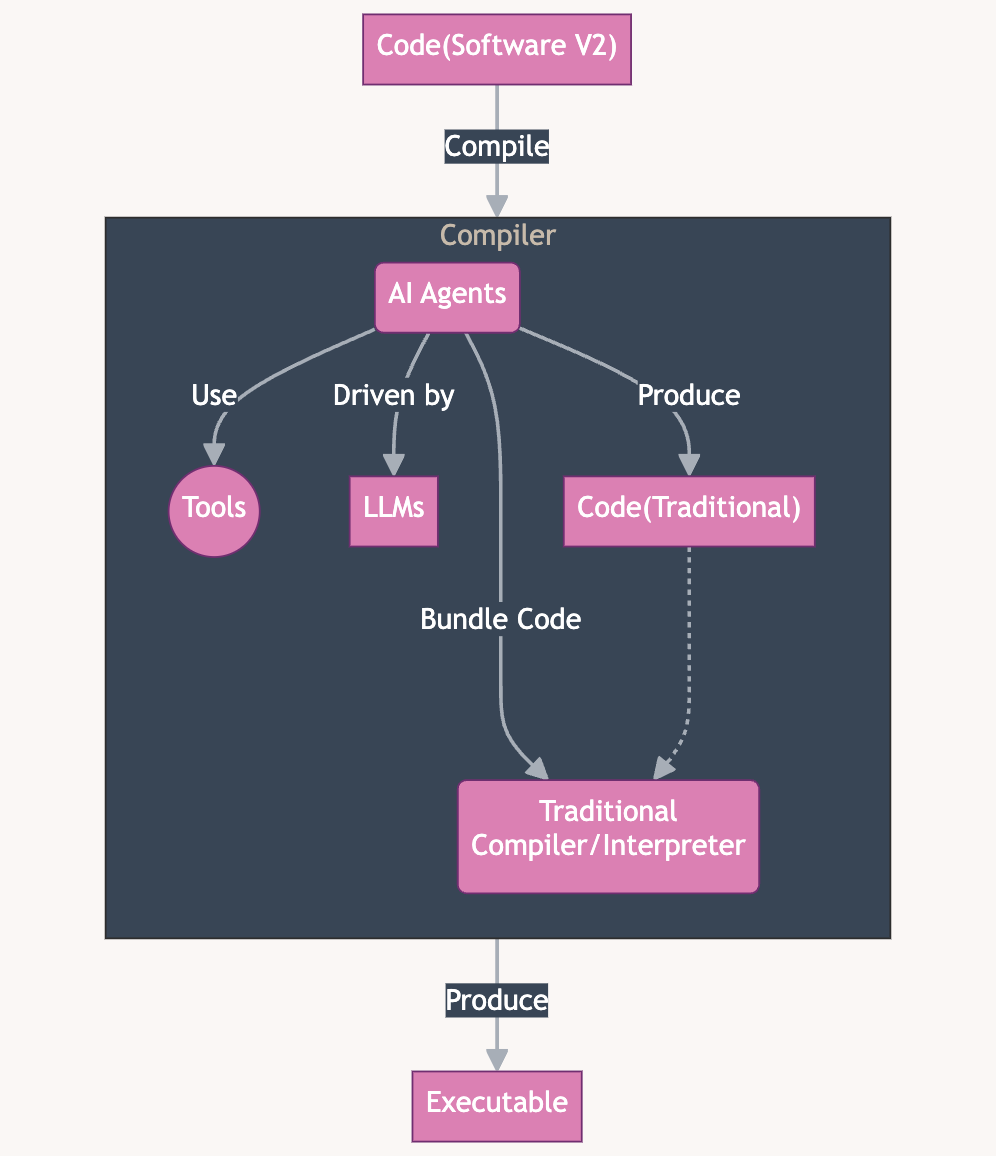
In the flowchart above:
- People produce Software V2 code and send it to the Compiler.
- Compiler is an agentic system, that uses various tools, from web search to static code analysis to build traditional code.
- The compiler outputs executable application that is ready-to-use.
Such a compiler might not just produce software and evolve it, it also can observe it in production environment and continuously improve it. And given advanced enough systems (compilers) like this might even proactively fix bugs, address user's queries, etc.
Impact on Software Development
Around 75% of development effort is wasted on "How". And this not only writing and maintaining code, but also the deployment effort. The last argument is not applicable for all types of software equally though. If we are talking about web applications this is very clear, for the native applications, may not be so much. As I personally am no expert in the latter I will keep it for people who actually know what they are talking about.
Just think about it, what if we can cut 3/4 of the effort needed to deliver functionality.
But I think pure numbers don't paint the picture well enough. Let's imagine what the ergonomics of such software development implies. I do not want to focus on development of brand-new applications, as we established above "green field" development is just but a small part of software engineering, even though it gets disproportionate attention. Imagine this: you have an application that is running and serving your users. You found a bug in said system. A "bug" is when your software behaves differently than you expect, that is all there is to it. Simply put, in terms of Software V2, you have not defined this requirement specifically. All you have to do to fix the bug is to provide the input that caused the "bug", and the desired output instead of actual. Then run our Software V2 compiler, and that is it.
If you are like me, and spent decent amount of time developing software, you know that the current state of affairs is not nearly as simple. This is how I normally do it:
- I write an automated test that reproduces this bug.
- Then I run the test with the application in debugging mode (if possible) and try to understand the flow and business logic. Depending on the size of an application that might be minutes or days.
- Then I fix the bug.
- In an ideal world, the application has an amazing test automation coverage, and I run all the tests, making sure that my change did not cause any functional regression.
The scenario above is very optimistic and simplified. There is a good chance that my change caused a regression, and I have to chase that new bug, and cycle starts over. Also, the chance that an application has rock-solid test coverage is slim.
In short, it takes hours, and sometimes even weeks to fix bugs using traditional method. For this reason we have "Known bugs" section in documentation. With Software V2 all you have to do is the step #1 in the normal flow. I argue that this approach cuts out more than 3/4 of the effort needed for maintenance.
New features flow would be very similar to the bug fix.
Now think about the impact on the focus of software engineers and other roles involved in the development. The focus now is almost purely on what the software does. It is now front and centre for everyone.``
Adoption barriers
I can identify three main category of issues people would have adopting Software V2:
- Reluctance to change
- Gaps in technology
- Legal/Moral issues
Let's look at each category in detail.
Reluctance to change
Going back to Kent Beck's article let's look at the arguments against compilers. Though his father's arguments were against C compiler, I bet you can see how those same arguments can be used today against tools that completely abstract code from you. Just instead of "assembly language", simply read "code":
- The compiler will never be as efficient as hand-coded assembly language & cycles are precious. The compiler is getting better.
- The compiler will never be able to cram as much code into as little space & space is precious. The compiler is getting better.
- The compiler takes longer to run than the assembler & compiler time is precious. The compiler is getting better.
While building Micro I have personally interviewed dozens of developers who use Micro. The only consistent complaint had been "I need to see the code." Not that software that Micro produces is not working correctly, or it is slow, or anything about "What" the software does. When I kept asking “Why do you want to see or edit code yourself” over and over, I always ended up with "I can't trust it" argument.
It is human nature to be skeptical of new things, especially when your peers are not using those. We are social animals and need validation. This technology as any other will go through the same process: Innovators → Early Adopters → Early Majority → Late Majority → Laggards.
Gaps in technology
As with any technology, it won't be perfect immediately. Also, some types of software is much better suited to the concept of Software v2 than others.
The thing is, that this approach can only benefit from current trend of LLMs becoming smarter. Companies pour millions of dollars into training better and better models. There is also so much research on how to use those models more effectively. I argue that at this stage of LLM performance, the latter is more important. But all in all, the velocity of this tech is almost unprecedented. ChatGPT is not even two years old, but is used by 82% of developers according to StackOverflow survey 2024.
I think the main problem with Software V2, is that it looks too radical today. Especially now that we have so many new "toys" we can play with that fuel the "old way." Which in turn means that the attention and the money go to generating more code for people to manage instead of reducing it. Which also means that investment for Software V2 is restricted.
It is a bit of a chicken-and-egg problem. People don't want to adopt a technology that is very radical and not yet "perfect". Which restricts resources for people building such systems (direct usage proceeds and investment since there is very little usage). Which tanks further development.
The thing is, it does not have to be perfect, it just has to be better enough than anything else. From that point market will correct the faults of our ways, as it almost always does.
Legal and Moral issues
I usually try not voicing my thoughts in this area. Since I am not a Legal expert nor am I a figure in Moral issues.
I know anecdotally that some companies forbid usage of AI assistants, both coding and chat due to legal concerns. And as much as I can relate to being cautious, I can also say that those decisions need to be regularly reviewed. If not, competitors who make a full use of those tools will run circles around the ones that do not.
I will not say more here, the point I want to make by adding this section, is that legal and moral part of all things AI is super unclear, and has to be taken seriously.
Conclusion
In this article, I argue that we are on the brink of a revolution in software development, comparable to the leap from Assembly to high-level languages. By shifting our focus from "how" to write code to "what" we want to achieve, we can transform the very foundation of our industry.
Imagine a world where data, in the form of input/output examples, becomes the new programming language—clear, unambiguous, and precise. This approach, Software V2, positions code as a liability and emphasizes the true asset: functionality. I propose a groundbreaking new "compiler" that translates these data-driven specifications into executable software, creating, maintaining, and evolving it without traditional code management.
The impact of this shift is profound. By focusing on functionality and reducing the effort spent on writing and maintaining code, we can cut ~75% of the development effort. This isn’t just an evolution of our tools; it's a complete reimagining of how we build software.
P.S.
I conceived the concept behind Software V2 August 2022, and then written PR FAQ* document on September 11, 2022. This happened before LLMs became the hottest thing there is and more importantly for me, before I knew what they are. I thought this might be possible without omnipotent LLMs, now (in my opinion) it is simply bound to happen!
If you are interested in reading the original PR FAQ I have written for Micro. If you read it though, please understand that this document is a thought exercise, so the events and features described in the document are imaginary (though a lot is true today too).
An Amazon-style PR FAQ document is a product development tool consisting of a mock press release and a detailed FAQ section. The press release outlines the product's vision, key features, and benefits as if it were already launched, while the FAQ addresses anticipated questions about functionality, audience, and technical details.
I use it to evaluate ideas, and helps me project the consequences of a product.


Comments ()